投資市場中,除了財報與技術指標, 新聞、輿論與市場情緒往往才是股價短期波動的最大推手。
過去我們需要花大量時間閱讀財經新聞、瀏覽論壇、分析專家評論,才能拼湊出市場情緒,但 AI 的出現,讓這一切變得輕鬆許多。今天,我們要用 Gemini 幫我們把新聞和社群文字「翻譯」成可理解的市場情緒解讀。
市場是人心的反射:股價不只是數字,還包含人們的信心與恐懼。
消息面影響波動:利多消息(如新產品發表、政策利好)常推升股價;利空消息(如財報不佳、監管收緊)則可能引發拋售。
社群放大效應:Twitter、PTT、Reddit 等論壇的輿論熱度,也可能短時間內放大價格波動。
我們這次使用NewsAPI來幫我們抓新聞。
優點:簡單、能用股票代號搜尋、JSON 結構清晰、支援全文與排序過濾
缺點:需要申請 API Key,Free Plan 有每日請求限制,但足以應用個人專案或練習。
申請步驟也很簡單,只要去NewsAPI.org就能夠用gmail申請API Key,這邊不多做解說。
python
import requests
import json
import time
import pandas as pd
import numpy as np
from datetime import datetime, timezone
import google.generativeai as genai
# 設定 Gemini
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel("gemini-1.5-flash")
NEWS_API_KEY = "YOUR_NEWSAPI_KEY"
def fetch_newsapi_news(ticker: str, max_items: int = 10):
url = "https://newsapi.org/v2/everything"
params = {
"q": ticker,
"language": "en",
"sortBy": "publishedAt",
"apiKey": NEWS_API_KEY,
"pageSize": max_items
}
resp = requests.get(url, params=params)
if resp.status_code != 200:
print("NewsAPI 抓取失敗:", resp.status_code, resp.text)
return pd.DataFrame()
data = resp.json()
rows = []
for item in data.get("articles", []):
rows.append({
"ticker": ticker,
"title": item.get("title") or "",
"publisher": item.get("source", {}).get("name") or "",
"published_at": item.get("publishedAt") or "",
"url": item.get("url") or ""
})
return pd.DataFrame(rows)
def sentiment_with_gemini(texts: list[str]):
results = []
for t in texts:
prompt = f"""
請判定以下文字的市場情緒傾向,輸出 JSON:
文字: {t}
輸出格式(僅 JSON):
{{
"label": "positive|neutral|negative",
"score": 0.0
}}
"""
try:
res = model.generate_content(prompt)
txt = res.text.strip()
except Exception:
txt = '{"label":"neutral","score":0.5}'
results.append(txt)
time.sleep(0.2)
return results
# 主流程
df_news = fetch_newsapi_news("AAPL", max_items=10)
if df_news.empty or df_news["title"].isna().all():
print("沒有抓到有效新聞標題。")
else:
titles = [t for t in df_news["title"].tolist() if t]
raw_scores = sentiment_with_gemini(titles)
labels, scores = [], []
for r in raw_scores:
try:
obj = json.loads(r)
labels.append(obj.get("label", "neutral"))
scores.append(float(obj.get("score", 0.5)))
except Exception:
labels.append("neutral")
scores.append(0.5)
df_news = df_news.loc[df_news["title"].notna()].reset_index(drop=True)
df_news["sentiment_label"] = labels
df_news["sentiment_score"] = scores
df_news = df_news.sort_values("sentiment_score", ascending=False).reset_index(drop=True)
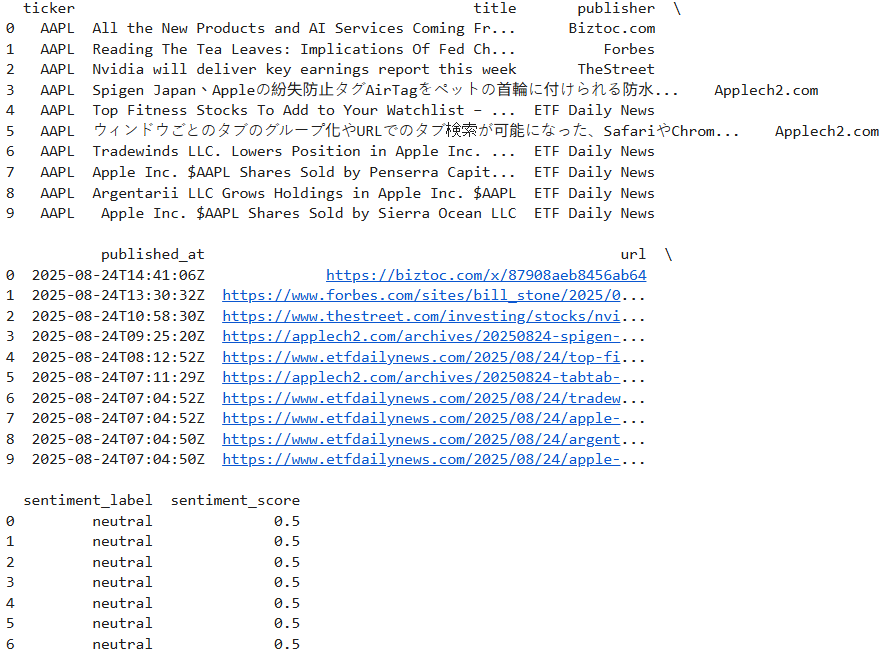
print(df_news.head(10))
使用說明:
記得填入 YOUR_NEWSAPI_KEY 和 YOUR_GEMINI_API_KEY。
df_news 若有資料,就會呼叫 Gemini 做情緒分析、輸出 sentiment_label 和 sentiment_score。
如果抓不到新聞,會直接輸出提醒。
我發現這份程式碼有的問題在於 Gemini 回傳的內容常常不是乾淨的 JSON,所以 json.loads(r) 常常失敗 → 直接 fallback 成 neutral/0.5。
所以我後來在 sentiment_with_gemini 裡加 嚴格 JSON prompt + 清理步驟 (正則抓取 {...} 部分),確保輸出能被成功解析。
python
import requests
import json
import time
import pandas as pd
import numpy as np
from datetime import datetime, timezone
import google.generativeai as genai
import re
# 設定 Gemini
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel("gemini-1.5-flash")
NEWS_API_KEY = "YOUR_NEWS_API_KEY"
def fetch_newsapi_news(ticker: str, max_items: int = 10):
url = "https://newsapi.org/v2/everything"
params = {
"q": ticker,
"language": "en",
"sortBy": "publishedAt",
"apiKey": NEWS_API_KEY,
"pageSize": max_items
}
resp = requests.get(url, params=params)
if resp.status_code != 200:
print("NewsAPI 抓取失敗:", resp.status_code, resp.text)
return pd.DataFrame()
data = resp.json()
rows = []
for item in data.get("articles", []):
rows.append({
"ticker": ticker,
"title": item.get("title") or "",
"publisher": item.get("source", {}).get("name") or "",
"published_at": item.get("publishedAt") or "",
"url": item.get("url") or ""
})
return pd.DataFrame(rows)
def sentiment_with_gemini(texts: list[str]):
results = []
for t in texts:
prompt = f"""
你是一個金融市場情緒分析器。
請只輸出 JSON 格式,不要輸出其他任何文字。
文字: "{t}"
JSON 格式範例:
{{
"label": "positive",
"score": 0.85
}}
規則:
- label 只能是 "positive"、"neutral" 或 "negative"
- score 必須介於 0.0 和 1.0 之間
"""
try:
res = model.generate_content(prompt)
txt = res.text.strip()
# 用正則強制擷取 { ... } 部分,避免多餘文字
match = re.search(r"\{.*\}", txt, re.S)
if match:
txt = match.group(0)
else:
txt = '{"label":"neutral","score":0.5}'
except Exception:
txt = '{"label":"neutral","score":0.5}'
results.append(txt)
time.sleep(0.2) # 避免 API 過快
return results
# 主流程
df_news = fetch_newsapi_news("AAPL", max_items=10)
if df_news.empty or df_news["title"].isna().all():
print("沒有抓到有效新聞標題。")
else:
titles = [t for t in df_news["title"].tolist() if t]
raw_scores = sentiment_with_gemini(titles)
labels, scores = [], []
for r in raw_scores:
try:
obj = json.loads(r)
labels.append(obj.get("label", "neutral"))
scores.append(float(obj.get("score", 0.5)))
except Exception:
labels.append("neutral")
scores.append(0.5)
df_news = df_news.loc[df_news["title"].notna()].reset_index(drop=True)
df_news["sentiment_label"] = labels
df_news["sentiment_score"] = scores
df_news = df_news.sort_values("sentiment_score", ascending=False).reset_index(drop=True)
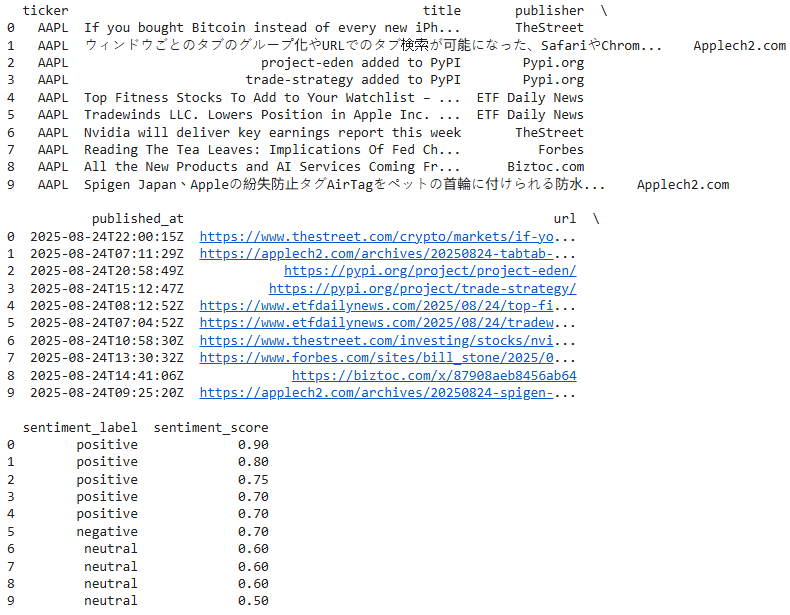
print(df_news.head(10))
Prompt 更嚴格 → 限制只能輸出 JSON。
正則清理 → re.search(r"{.*}", txt, re.S),只取 {...},避免亂七八糟的解釋文字。
保險 fallback → 失敗就塞 neutral/0.5。
python
# 安裝套件
!pip install -q feedparser pandas google-generativeai
import os, time, feedparser, pandas as pd, google.generativeai as genai
from urllib.parse import quote_plus
# 設定 API Key
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel("gemini-2.5-flash")
def fetch_google_news(query: str, lang="zh-Hant", region="TW", max_items: int = 20):
"""
從 Google News RSS 抓取新聞。lang/region 可改成 en/US 等。
"""
q = quote_plus(query)
url = f"https://news.google.com/rss/search?q={q}&hl={lang}&gl={region}&ceid={region}:{lang}"
feed = feedparser.parse(url)
rows = []
for entry in feed.entries[:max_items]:
rows.append({
"query": query,
"title": entry.get("title", ""),
"summary": entry.get("summary", ""),
"published": entry.get("published", ""),
"link": entry.get("link", "")
})
return pd.DataFrame(rows)
def sentiment_batch_gemini_bulk(headlines: list[str], summaries: list[str] | None = None):
"""
一次把多則新聞送進 Gemini,回傳 JSON 陣列結果
"""
import json, re
# 建立提示詞
prompt = "請閱讀以下多則新聞(標題+摘要),逐一評估市場情緒,最後輸出 JSON 陣列:\n\n"
for i, h in enumerate(headlines):
s = (summaries[i] if summaries else "") or ""
prompt += f"新聞{i+1}:\n標題: {h}\n摘要: {s}\n\n"
prompt += """
定義:
- label: positive / neutral / negative
- score: 0~1,越大越正面,約0.5為中性
- rationale: 1~2 句理由(中文,避免誇大)
請輸出 JSON 陣列,例如:
[
{"label":"positive","score":0.8,"rationale":"理由"},
{"label":"neutral","score":0.5,"rationale":"理由"},
{"label":"negative","score":0.3,"rationale":"理由"}
]
"""
res = model.generate_content(prompt)
# 嘗試取回文字
output_text = res.text.strip() if hasattr(res, "text") else res.candidates[0].content.parts[0].text.strip()
# 只取 JSON 陣列部分
match = re.search(r"\[.*\]", output_text, re.S)
if not match:
raise ValueError(f"模型輸出不含 JSON 陣列:\n{output_text}")
return json.loads(match.group())
# === 使用範例 ===
df_g = fetch_google_news("台積電", lang="zh-Hant", region="TW", max_items=15)
if not df_g.empty:
results = sentiment_batch_gemini_bulk(df_g["title"].tolist(), df_g["summary"].tolist())
# 把結果展開合併回 DataFrame
df_res = pd.DataFrame(results)
df_g = pd.concat([df_g, df_res], axis=1)
# 依分數排序
df_g = df_g.sort_values("score", ascending=False).reset_index(drop=True)
df_g.head(10)
穩定且不需額外 API:走 RSS,適合「主題/公司/產業」關鍵字
範例:關鍵字可用「台積電」「半導體」「AAPL」等

法遵/版權:抓取新聞請尊重來源與版權,建議只存「標題、時間、連結、情緒分數」,閱讀正文導流回原站。
節流:大量分析時請加 time.sleep() 或併批次處理,避免 API 限制。
去重/清洗有些 RSS 來源會重複或轉載,建議以 title+link 做去重。
健壯性:加上 try/except,遇到來源變動或空資料時不中斷流程。
今天了解了兩個穩定可用的新聞來源方案(NewsAPI、Google News),並且能即時把「新聞 → 情緒分數」量化,下一步就能把它和 技術面(RSI/MA)、基本面 一起打包,逐步形成你的日更投資快訊。
👉 明天(Day 13),我們將把這些模組串起來,自動產出一份「可讀、可執行」的 AI 投資報告💼📈

